本文出自Google,是一篇介绍Google Mobile App Store 推荐系统的工程性文章。全文虽只有四页,但却介绍了一个完整的推荐系统框架,可为工程实践、项目提供指导与借鉴。 原文地址:http://arxiv.org/abs/1606.07792
后期,Google在tensorflow中开放了该算法的API,详情参看google research blog
1. Introduction
Memorization 和 generalization 一直是推荐系统十分关注的问题。所谓 memorization 就是基于用户历史数据,挖掘出频繁出现的 item 或 feature。显然,基于 memorization 推荐的通常是那样与用户历史行为数据局部相关或者直接相关的物品。而 generalization 要是基于相关性之间的传递, 探索历史上没有出现的新的特征的组合,着眼于提高推荐的多样性。
google research blog对这两个词给出了更为形象的解释,将memorization类比成人类大脑的记忆功能,而generalization则是人类大脑的归纳功能。两者相辅相成,共同促进。
那么,能否将memorization和generation结合成一个性能更好的推荐模型呢?
基于这一想法,google 推出了 Wide & Deep Learning 模型,该模型能够高效的解决那些输入数据巨大且稀疏的分类或回归问题,如推荐、搜索和排序等
1.1 Motivation
- binary feature 都是基于one-hot 编码的,这样会使得所的的特征变得稀疏且高维。
- 不管是 memorization (细粒度的:
AND(user_installed_app=netflix, impression_app=pandora"))还是 generization(粗粒度的:AND(user_installed_category=video,impression_category=music))都可以通过cross-product transformation 的方法获得组合特征。但这种基于特征的工程的人工构造方法,耗时费力。且不能产生训练数据集中没有出现过的组合特征。 - 近年来,一些基于特征嵌入的模型(embedding-based model),如因子分解机和深度神经网络致力于训练低维稠密的向量来表示每一维特征。这样便可以通过向量之间的关系(距离,角度,点积)等来间接衡量所有特征之间的关系。
因此,作者提出一种 基于 特征组合的 linear model 和 基于embedding 的 feed-forward networks 联合训练互增强的框架。其具有很强的通用性,且能够有效的解决输入特征稀疏的问题。
2. Recommender System Overview

输入(query):用户/用户的query请求
输出(items):rank list
记录(logs):用户的操作:点击,下载等(表明用户喜好)
过滤(retrieval):当 item 数量很大时,rank 将会是一个十分耗时的工作。为了解决这一问题,会事先基于机器学习模型或人工定义的一些规则,筛选出最符合输入要求的候选 items。这个也就是工业上常用的召回策略
3. Wide & Deep Learning
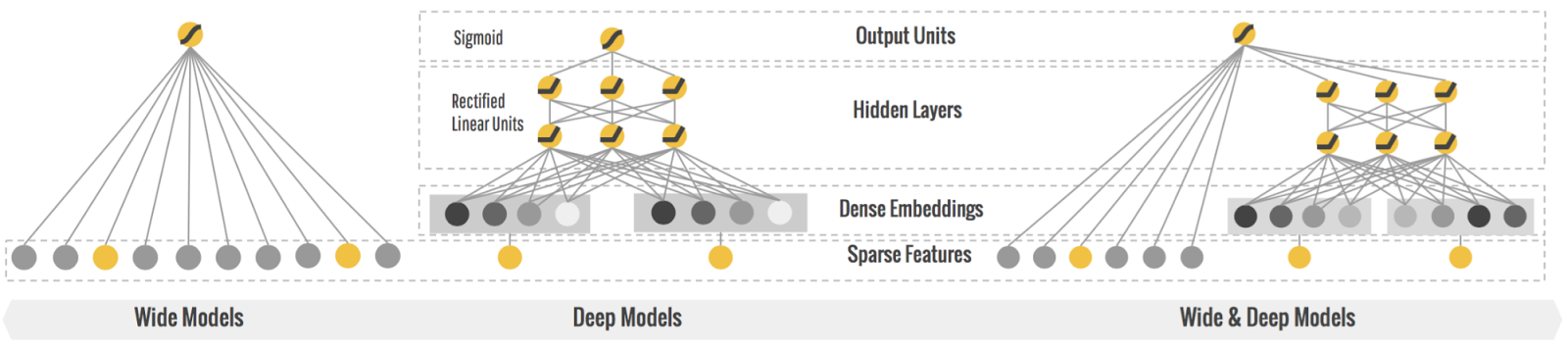
3.1 The Wide Component

Wide component 说白了就是一个广义线性模型:

其中,x 是输入的特征向量(d 维),w 是权重(d 维), b 是偏置。
第 k 维的 transform feature 的构造:

$c_{ki}$是示性函数,如果特征 i 在第 k 维 transform feature 中则为1, 否则为0。(显然,transform feature是人工事先定义的组合特征)
wide component 主要用于记忆、训练人工定义交叉特征
3.2 The deep Component
Deep component 是一个前馈神经网络,每个隐层的计算是:

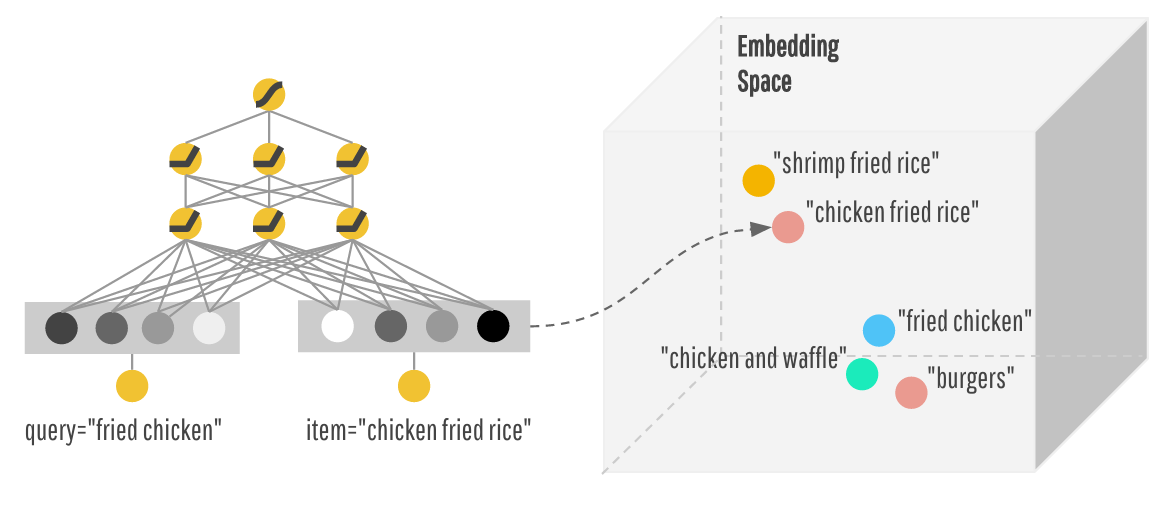
deep component主要用于训练、生成特征的embedding表示,这样基于向量之间的距离,找到在向量空间中比较相似的item
3.3 Joint Training of Wide & Deep Model

论文中说实现的上图的模型。但我始终不能理解。总感觉实现的应该是下面这个模型:
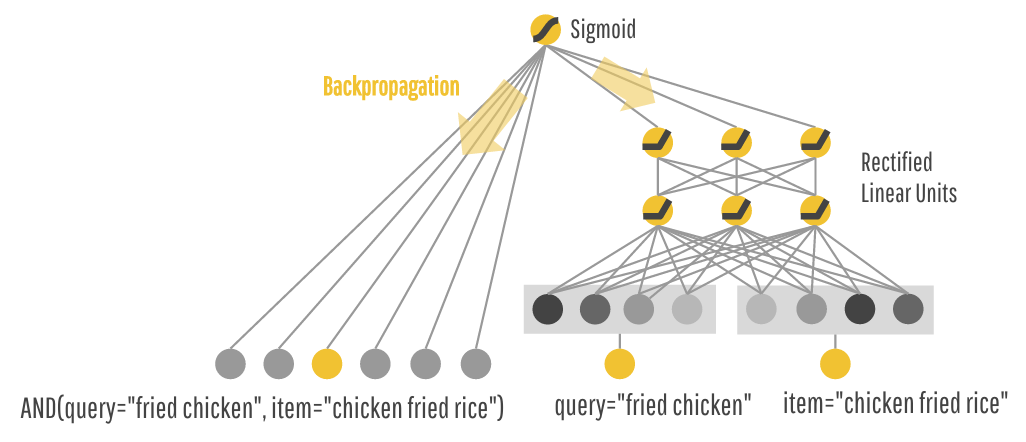
通过加权和将两部分的输出组合起来。
 结合图和公式,可以发现,模型的输入特性包含两类:
结合图和公式,可以发现,模型的输入特性包含两类:
- 基本特征+Cross-product transformations (wide component)
- 由 Deep Neural Networks 将所有特征(或类别特征)转化成的 dense embedding vectors
在Wide这边,作者们提出使用FTRL进行优化,而在Deep这边则使用了AdaGrad。 至此,模型已经介绍完毕,关于模型的训练不在此赘述,感兴趣的可以去tensorflow搜索本文模型的API。
这样模型既能基于wide component部分输入的交叉特征(人工定义的规则)找出符号用户喜欢的item,又能基于deep component部分,找出与item类似的可替代的item,提高推荐的多样性!
4. Wide & Deep Learning
- Data Generator:离散化,归一化
- Model training:在这一模块中所面临的一项挑战是:每当有新数据到来是,模型就必须重新训练。作者采用warm-starting 的方法加以解决:用上一模型的参数初始化新模型。
Model Serving:多线程并行

5. 实践
参照google公开的sample,自己调用API实践了下code,以加深多模型的理解、熟悉API的使用。
文件说明
Google
|---README.md
|---dataset.py 用于下载和预处理数据
|---wide_deep.py
|---tmp
| |---census_data 模型所需数据
| |---census_model 训练好的模型程度